Spring 프로젝트에서 Redis를 사용하여 빠른 검색어 자동 완성 구현하기 (1)
이번 포스팅에서는 Spring 프로젝트에서 Redis를 사용하여 검색어 자동 완성 기능을 구현하기 위한 로직과 자료구조를 소개해드리려 합니다. 실제 구현 코드와 트러블 슈팅 과정은 다음 포스팅에서 이어집니다.
검색어 자동 완성이란?
대부분 다 포털 사이트에서 많이 경험해보셔서 알고 계시겠지만 정확하게 자동 완성 기능에 대해 먼저 정의부터하고 넘어가겠습니다. 자동 완성은 Autocorrect 또는 Autocomplete라고 불리며 사용자가 입력한 낱말을 바탕으로 나머지 부분을 예측하여 미리 제공하는 기능입니다. 이를 통해 사용자는 모든 검색어를 직접 입력하지 않아도 의도했던 검색어를 더욱 빠르게 검색하거나 전체 검색 키워드가 잘 기억나지 않을 때 예측된 결과를 활용하여 조금 더 정확한 검색을 할 수 있습니다.
Redis를 사용한 이유
그렇다면 제가 자동 완성 기능을 구현할 때 왜 기존에 사용하던 RDB인 MySQL을 놔두고 굳이 Redis를 새로 띄워 사용했는지 궁금하실 수도 있습니다.
우선 제가 Redis를 사용하게 된 이유를 알아보기 전에 자동 완성 기능을 구현해야 하는 저희 프로젝트의 요구 사항에 대해 알아볼 필요가 있습니다. 저희 프로젝트를 간단히 소개하면 전국에 퍼져있는 다양한 가게를 지도로 띄워주는 모바일 애플리케이션입니다. 그 과정에서 사용자의 편의를 위해 검색 기능을 도입하게 되었고 더욱 편하고 정학한 검색 기능을 제공하기 위해 자동 완성 기능까지 구현하게 되었습니다.
이러한 자동 완성 기능은 앞서 설명드린 것처럼 사용자가 일부 글자를 입력할 때마다 매우 빈번하게 Backend 단으로 조회 요청을 날리게 되고 그때마다 서버는 검색 결과를 리턴해주게 됩니다. 즉, 더욱 정확한 검색어 예측을 위해서 조회 쿼리가 빈번히 발생할 수 밖에 없는 기능이고 저희 서비스와 같이 실제 운영을 하고 있는 서비스 같은 경우에 동시에 여러 사용자가 몰리게되면 빈번한 조회로 성능 저하가 불가피합니다. 더 나아가 자주 검색되는 키워드 같은 경우에는 캐시 서버를 도입하여 성능을 개선할 수 있는 여지가 있습니다.
이런 상황을 고려하여, 인메모리 DB 특성상 빠른 조회 성능이 보장되고 캐시 서버로도 흔히 사용되는 Redis를 사용하게 되었습니다. Redis는 NoSQL이라 다양한 형태의 데이터를 저장할 수 있고 인메모리 DB라서 디스크에 쓰고 읽는 것보다 훨씬 빠른 성능을 갖추고 있습니다. 하지만 메모리에 저장되다보니 휘발성을 띄어 서버가 내려가게 되면 데이터가 함께 유실됩니다.
저희 프로젝트에서는 검색 기능을 위한 조회 용도로만 사용되고 안전하게 저장되어야 하는 데이터들은 모두 RDB인 MySQL을 통해 디스크에 담고 있기 때문에 이 부분은 크게 문제가 되지 않았습니다. 다만, 서버가 껐다 켜짐에 따라 자동 완성 기능을 위해 미리 Redis에 저장해놓은 데이터가 모두 유실되기 때문에 Spring Bean이 뜨는 시점에 초기 데이터들을 Redis에 쓸 수 있도록 Redis 관련 Service 단에 @PostConstruct 애너테이션을 활용하여 빈이 생성됨과 동시에 초기 데이터들이 바로 저장될 수 있도록 구성하였습니다.
검색어 자동 완성 로직
그렇다면 지금부터는 검색어 자동 완성 기능을 구현하기 위한 Flow가 어떻게 되는지 알아보겠습니다.
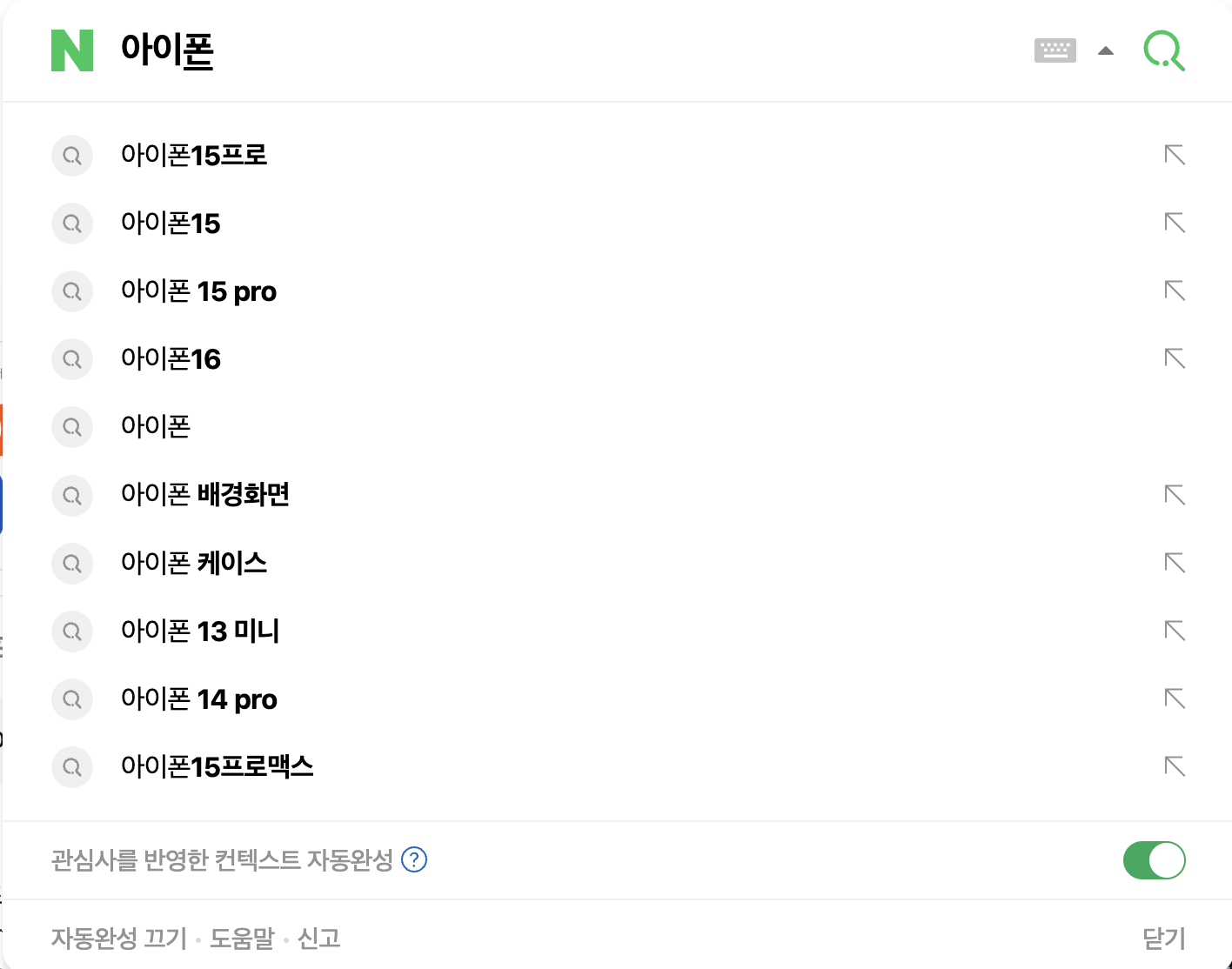
네이버에 ‘아이폰’이라는 검색어로 입력을 해보면 위와 같이 아이폰과 관련된, 아이폰이라는 키워드가 포함된 여러 자동 완성 검색 키워드들이 보여집니다. 이러한 자동 완성 기능은 제가 한 음절을 입력할 때마다 새로 갱신됩니다. 이를 착안하여 로직을 생각해보면 다음과 같이 정리할 수 있습니다.
- DB에서 검색 대상이 되는 컬럼의 데이터들을 음절 단위로 잘개 쪼갭니다.
- 쪼개진 음절을 모두 저장합니다.
- 저장된 음절들을 오름차순으로 정렬합니다.
- 정렬된 상태에서 사용자가 입력한 검색 키워드와 일치하는 곳의 인덱스를 찾습니다.
- 그 인덱스부터 그 뒤로 나오는 데이터들이 자동 완성된 검색어가 될 수 있는 후보들입니다.
위와 같은 흐름으로 구현한다면 쉽게 자동 완성 로직을 구현할 수 있을 것만 같습니다. 하지만 여기서 몇가지 주의해야 될 부분이 있습니다.
우선 첫째로, 모든 단어들을 음절 단위로 쪼개놓았기 때문에 불완전한 형태의 키워드들이 함께 조회됩니다. 예를 들어 ‘아이폰’이라는 값이 조회 대상으로 DB에 저장되어 있어서 이를 음절 단위로 쪼개 모두 저장한다고 치면 [아, 아이, 아이폰] 이런 식으로 쪼개져 저장될 것입니다. 이때 사용자가 ‘아’까지만 검색한다면 ‘아’, ‘아이’, ‘아이폰’이 모두 자동 완성 검색어로 노출될 것입니다. ‘아’가 노출되서는 안된다는 것은 너무나 자연스럽게 이해가 되지만 ‘아이’가 노출되는 것은 괜찮지 않느냐라고 생각하실 수도 있습니다. 하지만 ‘아이’는 자동 완성으로는 노출되서는 안되는 키워드입니다.
왜냐하면 처음 DB에 저장되어 조회 대상이 되었던 이름은 ‘아이폰’이었고 이 ‘아이폰’의 ‘아이’라는 글자와 ‘아이’라는 단어만 놓고 봤을 때 바로 떠오르는 단어와는 관련이 없기 때문입니다. 물론 ‘아이폰’이라는 키워드 외에 다른 단어들과 같은 경우, 특히 합성어 같은 경우에 음절 단위로 끊어 단어의 일부분만 잘라봤을 때 말도 되고 기존 단어와 문맥도 일치하는 단어가 존재할 수도 있습니다만 이 부분까지 고려하기에는 생각해야되는 부분이 너무 많아지기 때문에 저는 처음 조회 대상이 되는 완벽한 단어만 자동 완성 키워드로 노출되도록 설정해줄 것입니다. 이 로직은 완벽한 단어 뒤에 ‘*‘과 같은 문자를 두어 함께 저장하고 추후에 비즈니스 로직에서 ‘*‘가 포함되어 있는 단어만 자동 완성 검색어로 노출시켜주는 방식으로 간단히 구현할 수 있습니다.
둘째로, 음절 단위로 저장된 데이터 간의 경계값에 주의해야된다는 점입니다. 보통 이런 자동 완성 기능을 구현하게 되면 최대 자동 완성 검색어 노출 개수를 지정해서 노출하게 될텐데 아무리 오름차순으로 데이터가 정렬되어 있다고 하더라도 Limit 이내에 완전 다른 뜻을 가지는 경계값과 같은 단어가 뒤이어 존재하게 되면 어색한 검색어 예측을 하게 됩니다. 이런 단어들이 사용자에게 노출되면 사용자는 당연하게도 검색어 자동 완성 기능에 신뢰를 잃게 될 것입니다. 이를 막기 위해서 다양한 방식이 사용될 수 있지만, 저는 가장 심플하게 사용자가 입력한 검색어가 포함되는 경우에만 자동 완성 검색어로 노출될 수 있도록 구현할 계획입니다.
Redis의 SortedSet
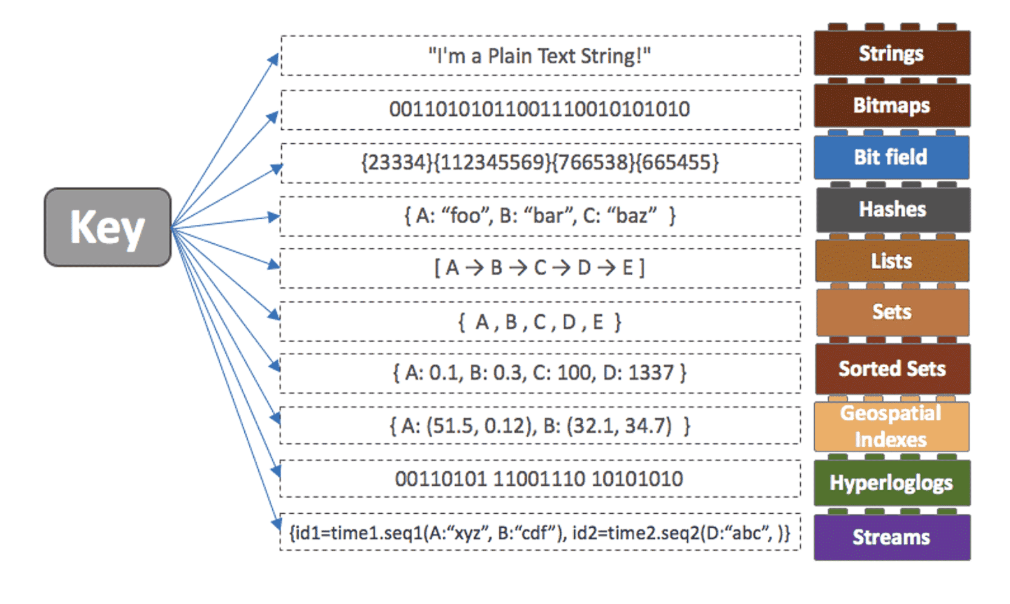
Redis에서 제공하는 자료 구조는 위에서 보시는 것처럼 굉장히 다양합니다. 그 중에서도 저희가 사용할 자료구조는 바로 SortedSet입니다.
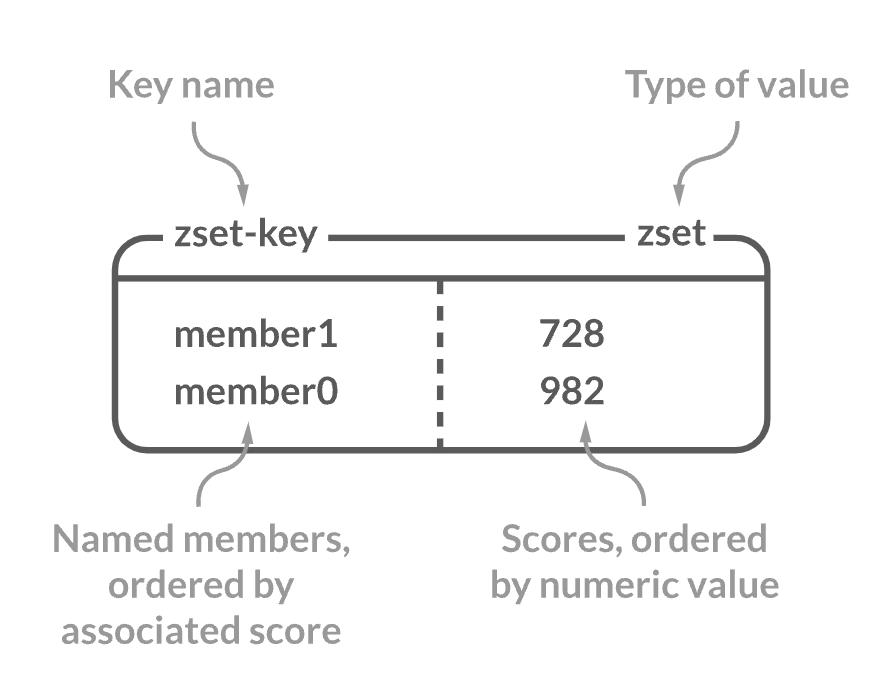
SortedSet은 이름 그대로 Set 형태의 자료구조인데 정렬을 제공합니다. 조금 더 자세히 살펴보면, Redis는 Key-value 쌍으로 데이터를 저장하게 되는데 이 Key 하나에 중복되지 않는 여러 멤버를 저장하며 이 각각의 멤버는 Score와 별도로 연결됩니다. 이렇게 저장된 데이터는 Score를 기준으로 모두 정렬되며 만약에 Score가 같다면 멤버 값의 사전 순서대로 정렬됩니다. 참고로 Score와 Member라는 이름에 걸맞게 이 Redis의 SortedSet은 게임 플레이어(멤버)의 점수를 대시보드로 구현할 때 많이 사용된다고 합니다.
각설하고 저희 또한 앞서 살펴봤듯이 정렬이 필요하고, 자동 완성하는 검색어가 중복되어선 안되기 때문에 현 상황에 사용하기 매우 적합한 자료구조라고 생각이 들었습니다. 또한, 정렬된 상태로 데이터들이 저장되기 때문에 인덱스를 이용하여 더욱 빠르게 조회할 수 있다는 성능적인 이점도 챙길 수 있습니다.
지금부터는 저희가 사용할 SortedSet의 주요 커맨드를 살펴보겠습니다.
1
2
3
ZADD [Key] [Score] [Member] //SortedSet의 특정 Key에 특정 Score를 가지는 Member 저장
ZRANGE [Key] [StartIndex] [EndIndex] //SortedSet의 특정 Key에 저장된 데이터를 오름차순으로 StartIndex부터 EndIndex까지 조회
ZREVRANGE [Key] [StartIndex] [EndIndex] //SortedSet의 특정 Key에 저장된 데이터를 내림차순으로 StartIndex부터 EndIndex까지 조회
이 외에도 더 많은 기능들이 있지만 자동 완성 기능 구현에는 필요하지 않기 때문에 생략하겠습니다.
마무리
지금까지 검색어 자동 완성 로직에 대한 간단한 소개부터 어떻게 구현할 수 있고 Redis를 사용한다면 어떤 자료구조를 사용해서 구현하면 좋을까지 살펴봤습니다. 다음 이어지는 포스팅에서는 실제 스프링 프로젝트에서 구현을 해보면서 코드를 어떻게 작성하면 좋을지, 그 과정에서 만나게되는 이슈들까지 함께 공유드리도록 하겠습니다.