Spring Project에서 158초 걸리던 Batch 작업을 병렬 처리하여 0.009초로 줄여본 이야기
이번 포스팅에서는 직전 포스팅에서 언급했던 것처럼 검색어 자동 완성 구현 로직 내 약 158초가 걸리던 Batch 작업을 병렬 프로그래밍을 통해 0.009초로 줄여본 경험을 공유드리려 합니다.
문제가 되던 Batch 작업
병렬 처리를 도입하게된 계기부터 전체적인 상황을 이해하고 싶으신 분이라면 검색어 자동 완성 기능 구현과 관련된 직전 포스팅들을 처음부터 읽고 오시는 것을 추천드리고, 단지 병렬 처리 과정을 보기 위해 들어오셨다면 이번 포스팅만 읽으셔도 무방합니다.
먼저, 문제가 되던 Batch성 작업 코드를 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
private void saveAllSubstring(List<String> allDisplayName) { //MySQL DB에 저장된 모든 가게명을 음절 단위로 잘라 모든 Substring을 Redis에 저장해주는 로직
// long start1 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
for (String displayName : allDisplayName) {
redisSortedSetService.addToSortedSet(displayName + suffix); //완벽한 형태의 단어일 경우에는 *을 붙여 구분
for (int i = displayName.length(); i > 0; --i) { //음절 단위로 잘라서 모든 Substring 구하기
redisSortedSetService.addToSortedSet(displayName.substring(0, i)); //곧바로 redis에 저장
}
}
// long end1 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
// long elapsed1 = end1 - start1; //뒤에서 성능 비교를 위해 시간을 재는 용도
}
위 코드가 바로 병목이 걸려 문제가 발생하던 코드인데 간단히 상황 설명을 드리면 다음과 같습니다.
검색어 자동 완성 기능 구현을 위해 MySQL DB에 저장된 모든 가게명에 대해서 음절 단위로 1글자씩 잘라낸 뒤 모든 Substring을 Redis에 저장해두는 1회성 Batch Job이 필요했고 그 로직 중 일부가 위 코드입니다. 참고로 저는 위 로직을 가게와 관련된 서비스 단인 StoreService에 대한 Bean이 만들어진 직후 딱 1번만 Atomic하게 실행시키기 위해 @PostConstruct 애너테이션을 활용하여 위 로직을 StoreService의 init() 로직에서 실행시켰습니다.
저희 Production DB에 총 가게가 약 51200개 정도 있고 가게 이름이 평균 6글자 정도라고 가정하면, 총 51200*6 = 307200번 정도의 Redis 연산이 순차적으로 실행되는 결과를 낳게됩니다. 그 결과 약 158초 정도의 시간이 걸렸고 일회성 Job이긴 하지만 이에 대한 개선이 반드시 필요하다고 생각이 들었습니다.
위 Batch 작업이 오래 걸리는 이유?
이 문제를 해결하기 위해 낮은 Performance가 나오는 이유에 대한 분석부터 시작했습니다. 이때 예상되는 문제는 총 2가지입니다. 첫 번째 문제는 약 307200번 정도의 긴 loop가 순차적으로 실행된다는 것, 이 부분에서 병목의 여지가 있다고 생각이 들었습니다. 또 다른 문제는 동일한 구조의 Redis 쿼리가 1개씩 총 307200번이 모두 나뉘어 실행된다는 점입니다. 이를 한번에 묶어서 보낸다면 네트워크적인 오버헤드를 줄일 수 있을텐데 말입니다.
문제 상황에 대한 원인 분석을 모두 마쳤으니, 지금부터 하나씩 해결해보겠습니다.
병렬 처리로 병목 해소
우선 첫 번째 문제부터 살펴보겠습니다. 연속적인 for loop 특성상 완전히 동일한 작업임에도 불구하고 이전 procedure를 모두 마치기 전에 다음 loop가 전혀 실행되지 못하고 대기하고 있습니다. 완전히 동일한 작업이 반복적으로 진행되는 것이기 때문에 병렬 처리를 적용하기가 더욱 쉽다는 생각이 들었고 이 로직에 병렬 처리를 적용하도록 결정했습니다.
하지만 병렬 처리를 적용하기 전에 반드시 고민해볼 문제들이 있습니다. 동시성 문제, 데이터 중복 문제 등이 있을텐데 우선 저는 Redis에서 제공하는 다양한 자료구조 중 SortedSet을 사용했기 때문에 데이터 중복 문제는 자료구조적으로 완벽하게 해결할 수 있었습니다. 동시성 문제 관련해서는 여러 스레드가 동시에 자원에 접근할 수 있는지, 무기한 교착 상태에 빠지지는 않는지, 각 스레드 작업 간의 충돌 등이 발생하지 않고 데이터 일관성이 보장되는지 등을 고민해볼 수 있을텐데, 다행스럽게도 제 로직에는 Redis의 SortedSet에 데이터를 저장하는 로직 밖에 없기도 하고 이 작업들이 서로 다른 스레드끼리 충돌을 발생시키는 스레드간 의존적인 작업이 아니기 때문에 문제가 없겠다는 생각이 들었습니다.
그래서 병렬 처리를 실제로 적용하기로 했고 적용한 코드는 다음과 같습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
18
19
20
private void saveAllSubstring(List<String> allDisplayName) {
// long start2 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
ExecutorService executorService = Executors.newFixedThreadPool(Runtime.getRuntime().availableProcessors()); //병렬 처리를 위한 스레드풀을 생성하는 과정
// ExecutorService executorService = Executors.newFixedThreadPool(4); //병렬 처리를 위한 스레드풀을 생성하는 과정
for (String displayName : allDisplayName) {
executorService.submit(() -> { //submit 메서드를 사용해서 병렬 처리할 작업 추가
// String threadName = Thread.currentThread().getName(); //멀티 스레드로 병렬 처리가 잘 되고 있는지 확인하기 위해
// System.out.println("threadName = " + threadName); //멀티 스레드로 병렬 처리가 잘 되고 있는지 확인하기 위해
redisSortedSetService.addToSortedSet(displayName + suffix);
for (int i = displayName.length(); i > 0; --i) {
redisSortedSetService.addToSortedSet(displayName.substring(0, i));
}
});
}
executorService.shutdown(); //작업이 모두 완료되면 스레드풀을 종료
// long end2 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
// long elapsed2 = end2 - start2; //뒤에서 성능 비교를 위해 시간을 재는 용도
}
저는 멀티 스레드를 이용해서 병렬 처리를 하기로 하였고 Java에서 기본적으로 제공하는 ExcutorService를 이용하였습니다. ExecutorService가 병렬 처리를 위한 스레드풀이라고 생각하면 됩니다.
이때 제가 주석 처리한 코드처럼 스레드풀에 담길 스레드 개수를 명시적으로 지정해줄 수도 있지만, 저는 머신 환경에 맞춰 유동적으로 스레드 변화를 주기 위해 현재 사용 가능한 프로세서 수만큼 스레드를 만들도록 구현하였습니다.
- Runtime.getRuntime().availableProcessors()
– 현재 JVM에 사용 가능한 총 프로세서 수를 반환- Executors.newFixedThreadPool()
– 고정된 수의 Thread를 가지는 ThreadPool 생성- executorService.submit()
– 해당 ThreadPool에 처리할 작업을 추가
– 매개 변수로는 Runnable, Callable을 받을 수 있으며 그렇기 때문에 람다식도 사용 가능- executorService.shutdown()
– shutdown()이 호출되기 직전까지 제출된 작업들은 모두 마무리 하고 ThreadPool을 종료- executorService.shutdownNow()
– 현재 진행중인 작업, 대기중인 작업 모두를 즉시 종료하고 대기중이었던 작업들을 List에 담아 리턴
참고로 위 메서드 요약 정보는 Oracle Java8 공식 Docs에 있는 내용을 참고하여 정리한 내용입니다.
병렬 처리 전후 성능 비교
기존에 단일 작업이었던 로직을 위처럼 멀티 스레드 기반의 병렬 처리로 바꿨을 때 얼마나 성능 향상이 됐는지 비교해봤습니다.
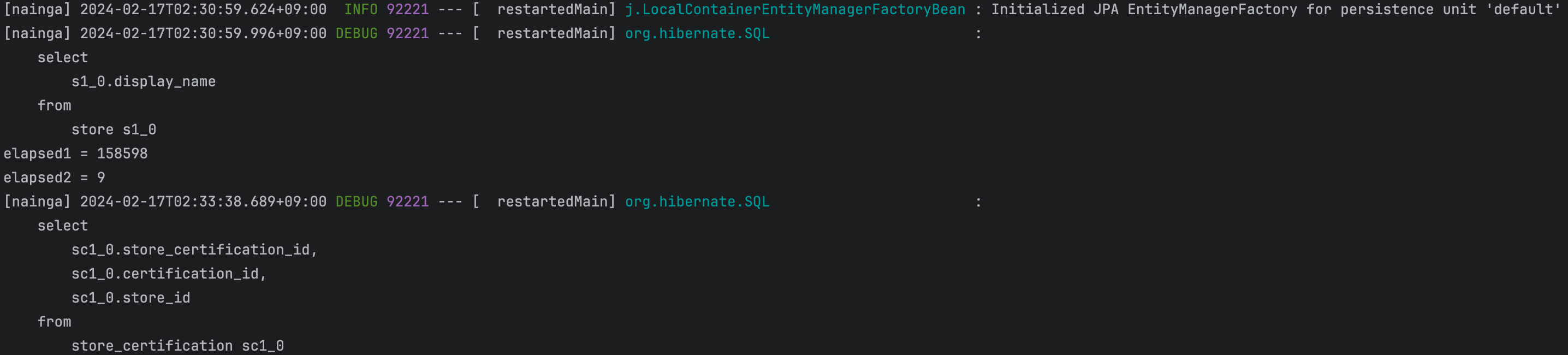
먼저 병렬 처리 적용 전 소요 시간은 위 사진 속 elapsed1입니다. 보시면 앞서 말씀드린 것처럼 158초가 걸리는 것을 확인할 수 있습니다.
다음은 병렬 처리 적용 이후의 소요 시간입니다. 이는 위 사진 속 elapsed2입니다. 시간이 0.009초대로 줄어들었습니다. 이를 계산해보면 기존 소요 시간의 0.00005% 수준으로 대폭 개선되었음을 확인할 수 있습니다. 이로써 오랜 시간이 걸리던 Batch 로직의 첫 번째 문제점을 성공적으로 개선해봤습니다. 다음은 두 번째 문제인 Redis 쿼리가 1개씩 나뉘어 나가는 문제를 해결해보도록 하겠습니다.
Redis 쿼리 묶어 보내기
참고로 다음 내용들은 Redis 공식 문서 내 Redis pipelining 문서를 참고하여 작성하였습니다.

Redis는 클라이언트-서버 모델을 사용하는 TCP 서버입니다. 즉, 클라이언트가 서버 측으로 쿼리를 보내고 유저는 서버로부터 응답을 받을 때까지 기다리게 됩니다. 즉 위와 같이 쿼리를 4개 연달아 보낼 때 먼저 보낸 쿼리에 대한 응답을 받기 전까지는 다음 쿼리를 보내지 못하며 응답을 기다리게 됩니다. 제 로직처럼 대규모 쿼리를 보낼 때 이런 부분에서 지연이 생길 수 있습니다.
뿐만 아니라, 클라이언트와 서버가 네트워크를 끼고 통신하다보니 네트워크 가용성에 따라 달라지는 Network Latency에 굉장히 의존적이라는 문제가 있을 수도 있습니다. 클라이언트가 서버에게 요청하고 응답을 받는 이 모든 여정에 걸리는 시간을 Round Trip Time(RTT)라고 부르는데 서버가 초당 100K 개의 요청을 처리할 수 있음에도 불구하고 RTT가 0.25초라고 가정하면 초당 최대 4개의 요청밖에 처리하지 못하게 됩니다.
그리고 단순히 RTT 문제 뿐만 아니라, socket I/O를 사용하는 관점에서 쿼리가 나누어서 실행되는 것은 굉장히 Costly하다는 문제가 있습니다. 이는 Read(), Write()와 같은 System Call을 사용하기 때문에 발생하는 문제인데 이는 유저 계층에서 시스템의 커널 계층까지 요청이 전달되어야 한다는 것이고 이에 따른 Context Switch 비용이 매우 큽니다.
이런 문제들을 해결하기 위해서 Redis에서는 쿼리를 묶어서 보낼 수 있도록 pipelining이라는 기능을 제공합니다. 이는 쉽게 말해서 클라이언트가 요청을 보낸 뒤 응답을 받지 않아도 이를 기다리지 않고 다음 요청을 바로 보낼 수 있도록 해주는 기능입니다. Pipelining을 적용하면 위 예시가 아래와같이 실행되게 됩니다.

여기서 근데 주의해야될 부분이 있습니다. 묶어서 보내는 것이 지연 요소를 줄일 수 있다는 것은 알지만 그만큼 응답도 묶어서 받기 때문에 서버는 그 동안 응답들의 모음을 메모리를 사용해서 대기열에 추가해둬야 합니다. 대규모의 데이터를 Pipelining을 통해 보내는 경우에는 이에 따라 과도한 메모리 점유 및 더 나아가 Out Of Memory 이슈가 발생할 수도 있으므로 적당한 크기로 나눠서 보내는 것이 좋습니다. 이에 대해 Redis Pipelining 공식 문서에서도 다음과 같이 경고하고 있습니다.
IMPORTANT NOTE: While the client sends commands using pipelining, the server will be forced to queue the replies, using memory. So if you need to send a lot of commands with pipelining, it is better to send them as batches each containing a reasonable number, for instance 10k commands, read the replies, and then send another 10k commands again, and so forth. The speed will be nearly the same, but the additional memory used will be at most the amount needed to queue the replies for these 10k commands.
그러면 지금부터 어떻게 Pipelining을 적용할 수 있을지 구현된 코드와 함께 살펴보겠습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
// long start3 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
redisSortedSetService.getRedisTemplate().executePipelined(
(RedisCallback<Object>) connection -> {
for (String displayName : allDisplayName) {
redisSortedSetService.addToSortedSet(displayName + suffix);
for (int i = displayName.length(); i > 0; --i) {
redisSortedSetService.addToSortedSet(displayName.substring(0, i));
}
}
return null;
}
);
// long end3 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
// long elapsed3 = end3 - start3; //뒤에서 성능 비교를 위해 시간을 재는 용도
위 코드는 Spring Data Redis에 Pipelining 주제로 작성된 공식 Docs를 참고하여 구현한 코드입니다. executePipelined() 메서드를 사용하여 pipeline을 열어주고, 그 안에 connection을 Parameter로 가지는 RedisCallback 함수를 넣어주면 됩니다. 이렇게 실행한 결과를 비교해보겠습니다.

위 사진 속 elapsed3이 기존 로직에 Redis의 Pipelining만 적용했을 때 소요 시간입니다. 원래 158초 정도 걸렸었는데 3초 정도 줄어들었습니다. 즉 저희가 걱정했던 네트워크 오버헤드에 따른 지연이 저희 환경에서는 생각보다 크지 않게 나타났습니다. 그래서 이번에는 한번 병렬 처리와 Redis pipelining을 동시에 적용시키면 어떻게 될지 궁금해서 아래와 같이 구현해봤습니다.
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
// long start4 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
redisSortedSetService.getRedisTemplate().executePipelined(
(RedisCallback<Object>) connection -> {
for (String displayName : allDisplayName) {
executorService.submit(() -> { //submit 메서드를 사용해서 병렬 처리할 작업 추가
redisSortedSetService.addToSortedSet(displayName + suffix);
for (int i = displayName.length(); i > 0; --i) {
redisSortedSetService.addToSortedSet(displayName.substring(0, i));
}
});
}
return null;
}
);
// long end4 = System.currentTimeMillis(); //뒤에서 성능 비교를 위해 시간을 재는 용도
// long elapsed4 = end4 - start4; //뒤에서 성능 비교를 위해 시간을 재는 용도

위 코드를 실행시켜 시간을 다시 재보면 제 첫 예상과는 다르게 오히려 병렬 처리만 적용했을 때보다 성능 저하가 발생했습니다. 이게 무슨 일인가 궁금해서 Redis의 동작 원리를 찾다가 다음과 같은 내용을 발견할 수 있었습니다.
Redis의 동작 원리
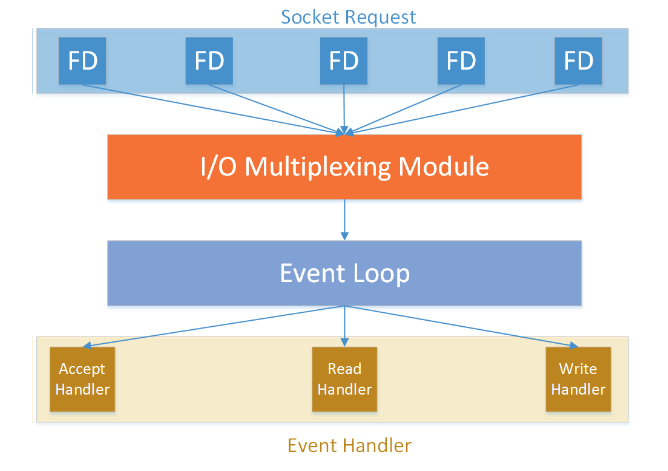
Redis는 위 사진처럼 소켓을 통해 들어오는 여러 클라이언트들의 요청을 동시에 처리할 수 있고(동시성), I/O Multiplexing단을 거쳐 Event loop로 들어와 클라이언트의 요청 타입에 맞게 Event들이 처리되는 방식입니다.
이건 전체적인 흐름이고 조금 더 자세히 공부하다보면 분명 Redis가 싱글 스레드인지 멀티 스레드인지에 대한 논쟁을 읽게 됩니다. Redis는 V6 이후부터 I/O Multiplexing 단에는 멀티 스레드를 적용하여 성능 개선을 하였고 실질적으로 Redis 연산이 수행되는 Event 단에는 그대로 싱글 스레드로 동작합니다.
이렇게 혼합해서 사용하는 이유가 뭔지, Redis 연산 로직에는 싱글 스레드 환경을 고집하는 이유가 뭔지 궁금해서 찾아보니 이유는 다음과 같습니다.
- 멀티 스레드를 사용하면서 발생하는 context-swtich 비용 절감
- 스레드 간의 자원 공유 문제가 발생하지 않음 (교착 상태, 경쟁 대기, 동기화 등)
- Atomic이 보장됨
이는 모두 이벤트 루프가 싱글 스레드여서 가능한 장점들입니다. 즉, 동기화 오버헤드 같은 추가 비용 없이 Atomic을 보장할 수 있습니다.
하지만 Redis는 이런 싱글 스레드 환경이라 병렬성을 가지진 못합니다. 하지만 동시성은 가지고 있습니다. 여기서 나오는 병렬성과 동시성도 굉장히 유사한 듯 헷갈리는 용어인데, 이 둘에 대한 정의를 정리하면 다음과 같습니다.
- 동시성: 서버가 단 하나의 계산 단위로 여러 클라이언트를 위한 여러 로직들을 실행하여 여러 클라이언트에 서비스를 제공할 수 있음을 의미
- 병렬성: 서버가 여러 작업을 동시에(여러 계산 단위를 사용하여) 수행할 수 있음을 의미
이해를 돕기 위해 추가적인 설명을 드리면, 점원과 고객의 예를 들 수 있습니다. 한 점원이 두 명의 고객을 동시에 돌볼 수는 있지만 한번에 한 사람의 주문만 받아줄 수 있다면 이 점원은 동시성은 가지고 있지만 병렬성은 갖추지 못한 것입니다.
그래서 결국 이전 얘기로 다시 돌아가서, 제가 생각했을 때 병렬 처리와 Pipelining을 동시에 적용했을 때 더 많은 시간이 걸린 이유는 애초에 병렬 처리를 통해 0.009초밖에 걸리지 않는 매우 짧은 시간에 처리가 가능한 로직이었고 Redis는 결국 싱글 스레드로 연산을 처리하기 때문에 처리 속도에는 둘 다 차이가 없지만 오히려 여러 스레드들에 대한 Pipelining 작업을 하는데 더 많은 추가 시간들이 소요되어 발생한 문제이지 않을까라는 생각이 들었습니다.
마무리
이로써 거의 총 3개의 포스팅에 걸쳐 검색어 자동 완성 기능 구현을 시작으로 Redis 적용, 이에 대한 Refactoring과 성능 비교까지 공유드렸습니다.
이에 대해 고민하고 명확한 근거를 찾고 기록까지하느라 정말 많은 시간이 걸리긴 했지만 궁금했던 부분들이 모두 시원하게 해결된 기분이라 마음만은 뿌듯합니다. 관련해서 잘못된 부분이 있거나 추가적으로 피드백 주실 부분이 있으시다면 편하게 댓글 부탁드립니다. 감사합니다.